- Published on
Managing Transactions in Microservices
- Authors

- Name
- Parminder Singh
The database-per-service principle in microservices dictates that each microservice possesses its own dedicated database. This fosters key advantages:
- Isolation: This setup safeguards each microservice's data. Changes or failures in one service's database won't have cascading effects on others.
- Autonomy & Agility: Teams can choose the database technologies that best suit the specific needs of each microservice. This allows for faster development and deployment cycles.
- Scalability: Databases can be scaled independently to match the demands of their respective microservices.
- Resilience: Failures in one service's database do not directly impact other services.

Photo by Denys Nevozhai on Unsplash
However, this pattern poses a significant challenge when transactions need to span across multiple services. In traditional monolithic applications, a single database typically manages transactions, ensuring:
- Atomicity: All transaction steps succeed or fail together.
- Consistency: The database remains in a valid state after the transaction.
- Isolation: Concurrent transactions don't interfere with each other.
- Durability: Committed changes persist even in the event of system failures.
In microservices, with transactions spanning across multiple services, ensuring data consistency and integrity across services (often independently owned databases) becomes complex.
Imagine an hotel booking service built using microservices, with the following services:
- Inventory Service: Manages available rooms and dates.
- Payment Service: Processes payments.
- Booking Service: Coordinates the overall reservation process.
Booking a room necessitates actions across the three services:
- Inventory Service: Check room availability and tentatively reserve.
- Payment Service: Process the credit card payment.
- Booking Service: Confirm the booking if the payment is successful, or roll back the tentative reservation if the payment fails.
This is where it gets tricky. If the payment fails, the failure needs to be communicated back to the Inventory Service to release held room. Since each service has its own database, there is no single, all-encompassing transaction to guarantee success or failure across all services.
Let's discuss two common patterns to address this challenge.
Two-Phase Commit(2PC)
2PC is a classic distributed transaction protocol that ensures consistency among multiple microservices involved in a single transaction. It works in two phases:
Prepare Phase: The transaction coordinator sends a "prepare" message to all participating microservices. Each microservice performs the necessary operations but holds the changes locally, not yet making them permanent. They reply with either a "ready to commit" or "abort" message.
Commit/Rollback Phase: If all microservices respond with "ready to commit", the coordinator sends a "commit" message, instructing them to make the changes permanent. If any microservice responds with "abort", the coordinator sends a "rollback" message, and all participants discard their changes.
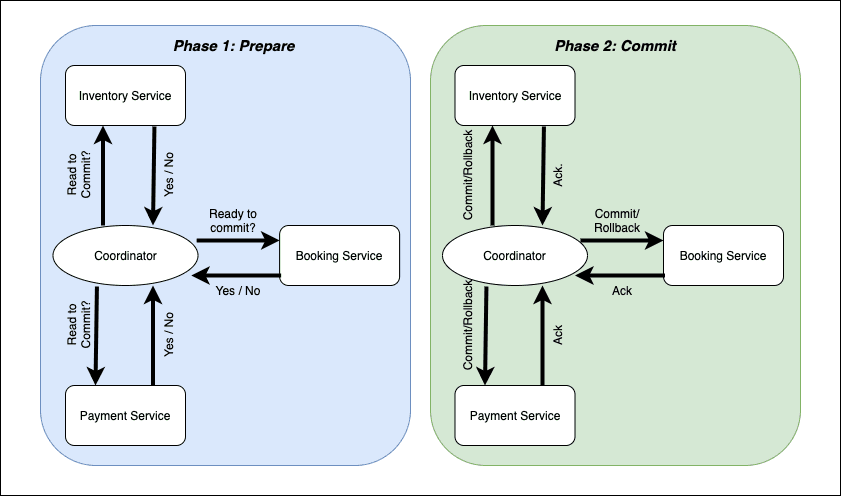 Two-Phase Commit
Two-Phase CommitChallenges with 2PC
Blocking: The prepare phase can block the entire transaction if a microservice is unresponsive.
Single Point of Failure: The coordinator is a single point of failure. If it fails, the transaction is stuck in an indeterminate state.
Performance: The two-phase commit protocol can be slow, especially when there are many participants.
Tight Coupling: The two-phase commit protocol tightly couples the services, making it difficult to add new services or change existing ones.
Eventual Consistency (Sagas)
This approach ensures eventual consistency, meaning there might be a period where data is not fully consistent across all microservices. The Saga Pattern is a sequence of local transactions where each transaction updates data within a single service. If one of these transactions fails, Sagas maintain data consistency by executing compensating transactions to undo the impact of the preceding transactions.
SAGAs can be implemented through choreography or orchestration.
Choreography: Services communicate directly, publishing and listening to events without a central coordinator. This approach promotes loose coupling but can lead to complex event chains that are hard to track. Orchestration: A central coordinator (an orchestrator service) explicitly tells the participating services what local transactions to execute. This simplifies the control flow but introduces a dependency on the orchestrator service.
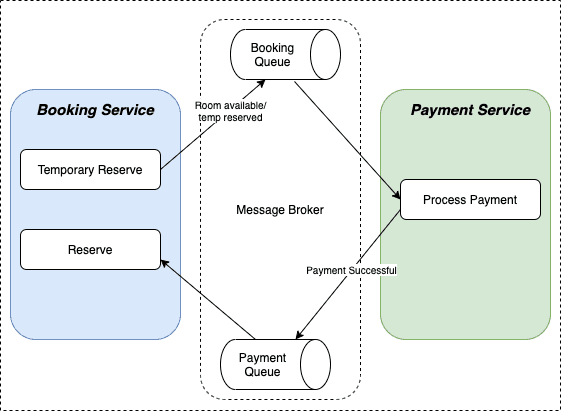 A simplified view of Choreography based SAGA
A simplified view of Choreography based SAGA| Aspect | Choreography | Orchestration |
|---|---|---|
| Coupling | Loose, services are more independent | Tighter, due to dependency on orchestrator |
| Complexity | High, due to indirect communication | Lower, thanks to explicit control flow |
| Flexibility | More, easier to add new services | Less, changes might require orchestrator updates |
| Visibility | Lower, as there's no central point of control | Higher, orchestrator provides a clear overview |
Sagas offer more flexibility and resilience in a microservices environment, making them a better choice for many scenarios. However, 2PC might be suitable for specific situations where strong consistency is crucial and transactions are short-lived.
There are several frameworks and libraries that provide support for implementing SAGAs in microservices, such as NServiceBus SAGA, Eventuate Tram SAGA, Axon, and others.
If you have used any of these frameworks, or have implemented SAGAs in your microservices, I'd love to hear about your experiences and challenges.
Reference
- SAGA Pattern by Chris Richardson
- Designing Data-Intensive Applications by Martin Kleppmann
- NServiceBus SAGA Documentation
- Eventuate Tram SAGA Framework
- Building Microservices by Sam Newman
- Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith
- Microservice Patterns by Chris Richardson