- Published on
Are LLMs getting closer to Human Like reasoning and AGI?
- Authors

- Name
- Parminder Singh

Photo by Steve Johnson on Unsplash
Imagine if I asked you how to design a system that can automatically detect and fix bugs in any piece of software. This question is complex and a I would likely break it down into smaller sub problems. Here's how I might approach it:
- What kinds of software are we considering? (web apps, mobile apps, etc)
- What categories of bugs do we need to detect? (logic errors, security vulnerabilities, performance issues)
- What techniques can be used to identify these bugs? (static analysis, dynamic testing, machine learning)
- How can we automatically fix the detected bugs? (code modification, configuration adjustments, redundancy mechanisms)
- How do we measure the effectiveness of the system and ensure it doesn't introduce new problems?
Humans are capable of complex reasoning. When posed with a problem, we break it up into smaller steps and sort of walk through it. Each step may have further problems/solutions. We iteratively go through these and learn what works and what doesn't. When we face a similar problem again, we follow the same process but this time also use our learnings. This ability to adapt and learn from experience is essential for solving real-world challenges.
Most AI models up until now were not fully capable of this complex reasoning tasks that require multi-step thinking and adaptive learning. Last month OpenAI released o1 which addresses these challenges by incorporating Chain-of-Thought (CoT) and Reinforcement Learning (RL) to achieve near-human reasoning capabilities.
Chain-of-Thought (CoT) is a technique that allows AI models to mimic this human-like reasoning process, by breaking down a problem into a sequence of intermediate steps. CoT enables AI to tackle more complex tasks that require logical reasoning and planning.
Reinforcement Learning (RL) is a learning paradigm that enables AI models to learn from their experiences. Similar to how humans learn through trial and error, RL involves rewarding desired behaviors and discouraging incorrect ones, allowing AI models to improve their performance over time.
OpenAI's o1 model combines CoT and RL to achieve near-human reasoning capabilities. According to tests, o1 demonstrates significant improvements in tasks involving logical reasoning, common sense, and mathematical problem-solving. Next upcoming updates to this model are even more powerful. Checkout the performance stats here.
With o1 and other models that incorporate critical reasoning, current applications will see enhanced performance and capabilities because of improved accuracy, ability to handle increased complexity and better decision making.
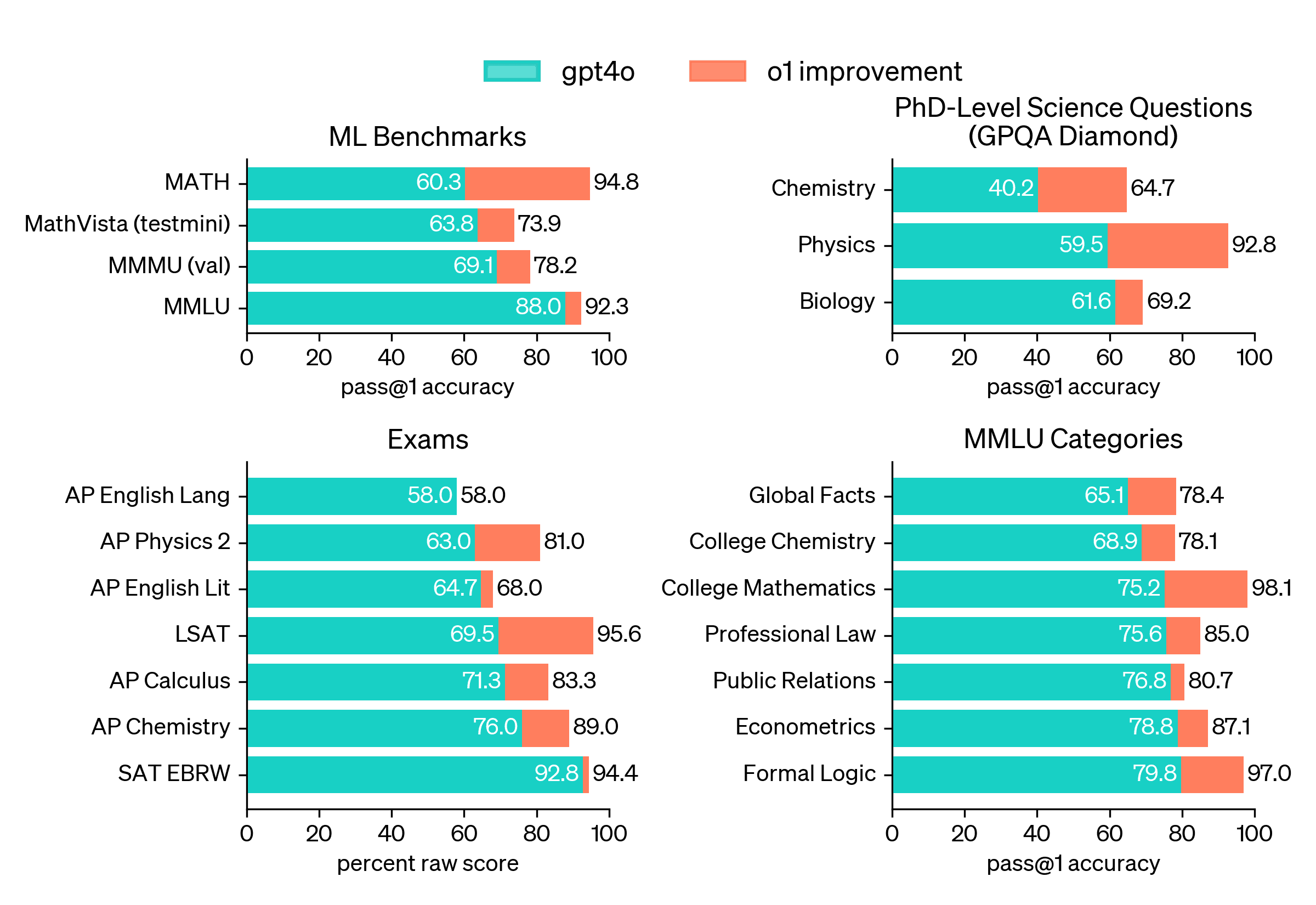
A note on MMLU (Measuring Massive Multitask Language Understanding): MMLU is a benchmark designed to evaluate the knowledge and problem-solving abilities of language models across a wide range of subjects. It covers many diverse tasks, from elementary mathematics and US history to more specialized areas like law and ethics. MMLU provides a comprehensive assessment of a model's general understanding and reasoning capabilities.
Advancements like this are a step closer to Artificial General Intelligence (AGI). Of course there's a long way to go and address challenges like hardware limitations, diversity of data used for learning, incorporating security and ethics, etc.
Have you played with o1? What new use cases can you can think of?