- Published on
Implementing RAG with OpenAI assistants
- Authors

- Name
- Parminder Singh
RAG is one of the most common use cases that has been implemented in the past couple of years. Retrieval Augmented Generation (RAG) is a technique that enhances the capabilities of LLMs by combining them with external knowledge sources. It involves retrieving relevant information from a knowledge base, incorporating it into the LLM's context, and then generating a response that leverages both the LLM's internal knowledge and the retrieved information. Building RAG applications requires integrating various components like vector databases and search algorithms, which can be quite involved. In this blog we'll briefly talk about RAG basics and leveraging OpenAI's assistants to build simple RAG applications.

Photo by Christopher Burns on Unsplash
Let's take the example of a chatbot that a business adds to their website to answer user queries about their products, FAQs, user manuals, etc.
To make this work, on a high level, the following things happen when user enters a query in the chatbot:
- Understand what user means in the business context and derive the intent
- Use the derived intent to query the business knowledge (FAQs, manuals, site, etc.)
- Formulate a response in natural language to display to the user.
Let's walk through on how would we implement this.
Understanding User Query: Natural Language Understanding (NLU) involves techniques like intent recognition (identifying the user's goal/intent), entity extraction (identifying key information related to intent like names, places, dates, etc.), and sentiment analysis. Libraries like spaCy, NLTK, and Stanford CoreNLP offer pre-trained models and functionalities for various NLU tasks. Cloud-based NLP options like Google Cloud Natural Language API can be used as well.
Matching with Content: Once we know the intent, we need to find a match. To achieve this, we can leverage vector databases. Check out my previous article on using vector databases in creating recommendations. Under the hood, this involves creating embeddings (numerical representations) using pre-trained language models like BERT or Sentence-BERT. These embeddings capture the semantic meaning of the text. Techniques like vector similarity search, approximate nearest neighbor search can be used to find similar embeddings in datasets. There are various libraries like Faiss and Annoy that can help in ANN search. Cloud based Vector databases and solutions like Pinecone. Weaviate and Elastic Search can be used for managing and searching large collections of embeddings.
Response Formulation: Using an LLM like GPT-4, and prompt engineering, we then create human-like text response from what we've found in the previous steps.
To summarize, using the above techniques, Retrieval involves finding relevant information from a vast knowledge base. Augmentation enhances the LLM's understanding with the retrieved information, like giving it extra context. And Generation produces new text based on the combined knowledge of the language model and the retrieved information.
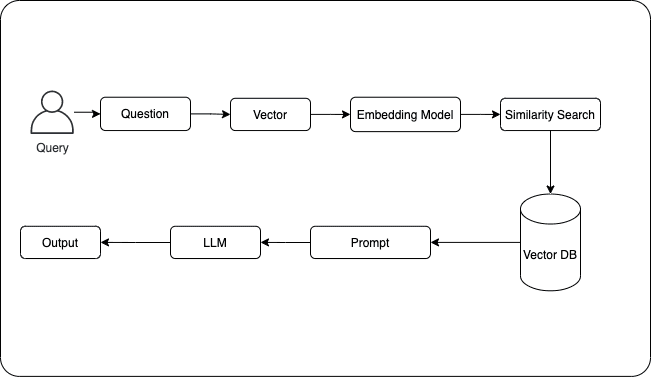
General RAG flow - Diagram by author
OpenAI's assistant and vector store APIs can now be used to implement simple RAG applications without weaving together different tools/libraries/steps mentioned above.
Assistant is basically purpose built AI that uses OpenAI's models and can call assistant "tools". Tools are a conduit that enable assistants to perform tasks and interact with your application/data. The file search tool helps augment the assistant with custom knowledge from outside it's model (knowledge in our documents, for example). As of today, the other tools that are supported are Code Interpreter and Function Calling. Vector Stores give the File Search tool the ability to search within files. When a file is added to a vector store, it is automatically parsed, chunked, embedded and stored in a vector database that's capable of both keyword and semantic search.
To demonstrate some of the capabilities of the OpenAI assistant APIs and get a basic understanding, I built a RAG application that can search files on my laptop and summarize them. Full code can be accessed at this GitHub repo. It is a command line application that prompts the user to enter a query. This query is then processed via the assistant. Presented below are steps and parts of sample code.
Upload your files using Vector Store APIs This will allow OpenAI to parse and chunk our documents, create and store the embeddings, and use both vector and keyword search to retrieve relevant content to answer user queries.
async function vectorizeFiles(folderPaths) {
const files = getFilesToIndex()
const fileStreams = files.map((path) => fs.createReadStream(path))
let vectorStore = await openai.beta.vectorStores.create({
name: process.env.VECTOR_STORE_NAME || 'AssistantRAGFileStore',
})
await openai.beta.vectorStores.fileBatches.uploadAndPoll(vectorStore.id, {
files: fileStreams,
})
console.log('Finished uploading files to vector store')
return vectorStore.id
}
Create assistant Creating an assistant involves configuring the model and instructions that will be used under the hood. It also involves attaching tools.
async function createAssistant(paths) {
const assistant = await openai.beta.assistants.create({
name: process.env.ASSISTANT_NAME || 'File Assistant',
instructions:
process.env.DEFAULT_INSTRUCTIONS ||
"You are an assistant who can help users find files on their computer, summarize them and provide information about the files. You can search for files by name, type, content or symantics. DO NOT show any sensitive information like name, address, SSN, date of birth, in your responses. Hide and redact them if needed. If the question is not about the document or can't be found in documents, you can use your own knowledge to provide the answer.",
model: 'gpt-4o',
tools: [{ type: 'file_search' }],
})
const vectorStoreId = await vectorizeFiles(paths)
//attach the vector store created earlier
await openai.beta.assistants.update(assistant.id, {
tool_resources: { file_search: { vector_store_ids: [vectorStoreId] } },
})
return assistant.id
}
Search
Message, Thread and Run APIs allow us to query the assistant in a contextual and conversational manner.
//create thread
const thread = await openai.beta.threads.create()
//create message
await openai.beta.threads.messages.create(thread.id, {
role: 'user',
content: USER_QUERY,
})
//create run in stream mode. As and when results are returned they are printed here.
openai.beta.threads.runs
.stream(threadId, {
assistant_id: assistantId,
})
.on('messageDone', async (event) => {
if (event.content[0].type === 'text') {
const { text } = event.content[0]
const { annotations } = text
let citations = []
let index = 0
for (let annotation of annotations) {
text.value = text.value.replace(annotation.text, '[' + index + ']')
const { file_citation } = annotation
if (file_citation) {
const citedFile = await openai.files.retrieve(file_citation.file_id)
citations.push(citedFile.filename)
}
index++
}
console.log(text.value)
// print sources where search results were found from
citations = [...new Set(citations)].map((c, i) => `${i + 1}. ${c}`)
console.log(citations.join('\n'))
console.log('\n\n')
}
})
Conclusion
OpenAI Assistant APIs offer a simple and straight forward approach to building simple RAG applications. However, when dealing with large-scale applications or complex requirements, leveraging and integrating with dedicated vector databases and specialized tools/services can offer greater efficiency and flexibility. Also be aware of the costs.
Have you built RAG applications? What use cases did you solve? What were some challenges that you faced?
Further Reading
- Assistants API Overview
- Vector Databases
- What is RAG - 1, 2