- Published on
ONNX and running models in the browser
- Authors

- Name
- Parminder Singh
When ML models are trained and run, the frameworks used to train them generate the model output in a format that is specific to that framework. The framework also provides a runtime that can run the model in a given environment in an optimized way. However, if the model needs to be run through a different framework or in a different environment, the model needs to be converted to the format that the new framework understands. Open Neural Network Exchange (ONNX) is a framework that solves this interoperability challenge. It provides a way to convert models from one format to another and also provides a runtime that can be used to run the model in a given environment.
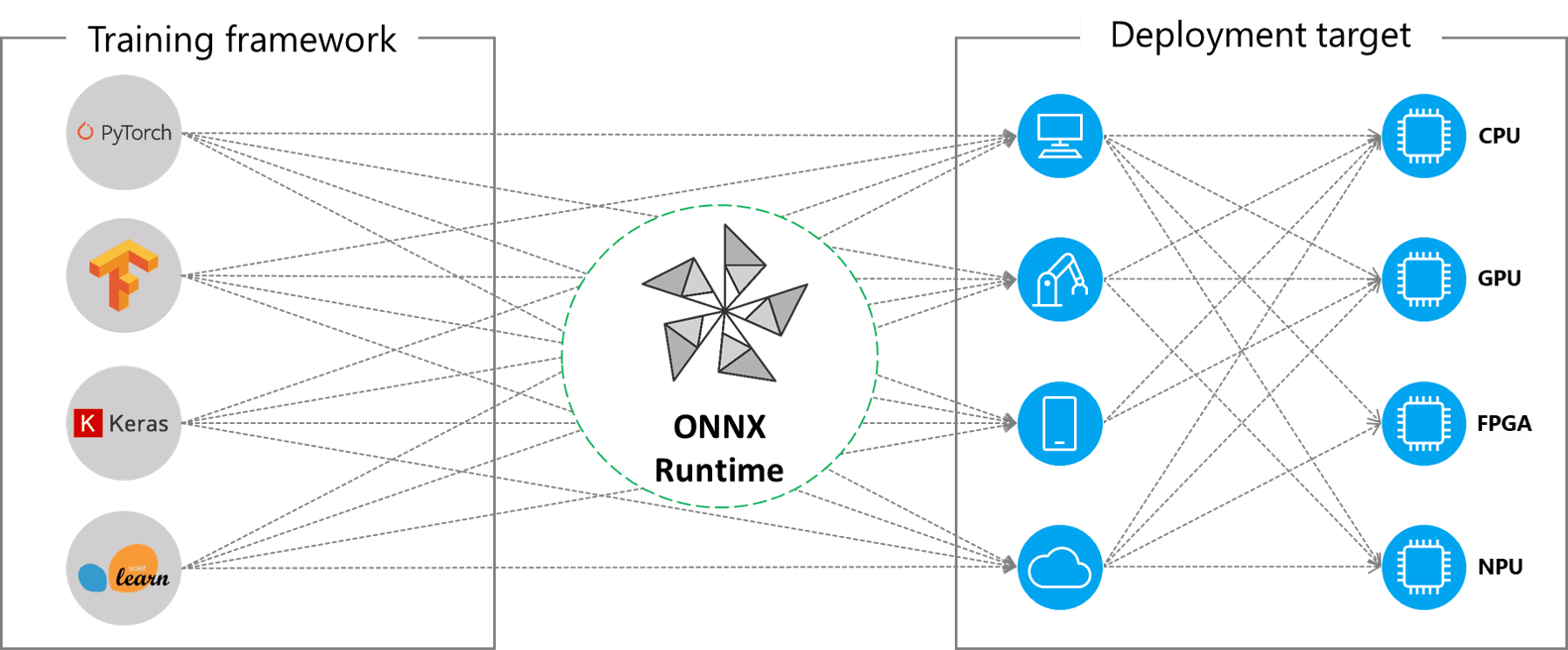
ONNX Runtime Execution Providers Source
ONNX can be thought of as an intermediary representation of the model. It is a common format that can be used to represent models trained in different frameworks. ONNX provides a set of operators and data types that are common across different frameworks. These operators can be used to represent the operations in the model. The model is represented as a graph where the nodes are the operators and the edges are the tensors that flow between the operators. The graph can be serialized into a file that can be read by the ONNX runtime. The ONNX runtime can then execute the model on a given hardware platform.
While not exactly like the JVM or CLR for programming languages, ONNX is a runtime that can be used to run models in a given environment. The runtime is optimized for the given hardware platform and can execute the model in an efficient way. While ONNX shares the goal of platform independence with the JVM and CLR, it's important to note that ONNX works at the level of model structure and parameters, not executable code. The JVM compiles code and ONNX converts models.
Beyond interoperability, portability, and runtime, ONNX also empowers model optimization (like quantization and pruning), facilitates easier deployment to diverse hardware, and plays a growing role in MLOps.
Two key challenges in MLOps are model serving and version management. Model serving, the process of deploying trained models for use in applications, is simplified by ONNX by allowing you to deploy the same model to different platforms (cloud, edge) without modification. This streamlines the process and reduces the risk of errors. ONNX models can be readily deployed on various serving systems, streamlining the integration of models into production pipelines. Also, ONNX's unified format addresses the complexities of managing model versions across different machine learning frameworks, ensuring consistent transfer and deployment.
In the last post, I spoke about what is Quantization and how can it help you run your models on lower powered hardware. We quantized a sentiment analysis model using PyTorch. Continuing from there, I will take the same model and quantize it using ONNX and then using the ONNX runtime, run the model in the browser.
Before looking at the code, try the demo below. Open the dev tools to see that there's no network call being made and the model is running locally. Enter some text in the text area and click on the "Test" button. The model will predict if the sentiment is positive or negative. (The first time you run the model, it might take a few seconds to load.)
Steps:
- Convert the model to ONNX format. We will use torch to convert the model to ONNX format.
#### The code below is a continuation from the previous post
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
# Export model to ONNX (fixing input format issue)
torch.onnx.export(
model,
(input_ids, attention_mask),
"model.onnx",
export_params=True,
opset_version=13,
input_names=["input_ids", "attention_mask"], # Match the inputs
output_names=["output"],
dynamic_axes={ # Allow variable-length inputs
"input_ids": {1: "seq_length"},
"attention_mask": {1: "seq_length"},
}
)
- Quantize the model using ONNX.
from onnxruntime.quantization import quantize_dynamic, QuantType
# Define paths
onnx_model_path = "model.onnx" # Path to the original ONNX model
quantized_model_path = "quantized_model_dynamic.onnx" # Path to save the quantized model
# Apply dynamic quantization
quantized_model = quantize_dynamic(
onnx_model_path,
quantized_model_path,
weight_type=QuantType.QInt8 # Quantize weights to int8
)
- Load the model in the browser and run inference in the browser. Please note that the code can be made a lot simpler by wrapping the onnx model and ingerence code into a WASM module, and then using the module in the browser. For simplicity, I will include the full code within the HTML/JS code. Most of the lines in the code below have comments to explain what they are doing. On a high level:
- the code tokenizes the input text,
- converts it into a format that the model understands,
- runs the model and then converts the output into a human readable format. In the example model we used, its doing sentiment analysis and the output is either positive or negative.
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js"></script>
<script type="module">
// AutoTokenizer helps in converting the text into tokens which is the input format for the model
import { AutoTokenizer } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers'
async function runInference(userInput) {
// Load the tokenizer for the `distilbert-base-uncased-finetuned-sst-2-english` model.
// This model is a lightweight version of BERT, pre-trained for sentiment analysis (positive/negative).
// read mode: https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english
const tokenizer = await AutoTokenizer.from_pretrained(
'Xenova/distilbert-base-uncased-finetuned-sst-2-english'
)
// Convert the input text into tokens (numerical representation).
// The `return_tensors: "np"` argument ensures the output is in NumPy array format.
// NumPy arrays are special types of arrays used in AI models to process numerical data efficiently.
const encoded = await tokenizer(userInput, { return_tensors: 'np' })
console.log('Tokenized Input:', encoded)
// Extract `input_ids` and `attention_mask` from the tokenized input.
// These are required inputs for BERT-based models.
// - `input_ids`: The tokenized representation of the words.
// - `attention_mask`: Tells the model which tokens are real words and which are padding.
const inputIdsArray = encoded.input_ids.data.map((id) => BigInt(id))
const attentionMaskArray = encoded.attention_mask.data.map((mask) => BigInt(mask))
// Get the length of the tokenized sequence (how many words/tokens were processed).
const sequenceLength = inputIdsArray.length
// Load the ONNX model. The previous step shows how to convert the model to ONNX format.
// Refer to my previous blog post for reference.
const session = await ort.InferenceSession.create('runnable/quantized_model_dynamic.onnx')
// Convert the input IDs into an ONNX-compatible tensor which is 64-bit integer.
const inputTensor = new ort.Tensor('int64', new BigInt64Array(inputIdsArray), [
1,
sequenceLength,
])
// read about attention masks: https://blog.lukesalamone.com/posts/what-are-attention-masks/
const attentionMask = new ort.Tensor('int64', new BigInt64Array(attentionMaskArray), [
1,
sequenceLength,
])
// Prepare the input data for the model (named inputs expected by ONNX).
const feeds = { input_ids: inputTensor, attention_mask: attentionMask }
// Run ONNX inference
const results = await session.run(feeds)
console.log('Raw Output Logits:', results)
// Extract the model output tensor (logits - raw scores before softmax).
const outputTensor = results[Object.keys(results)[0]]
const outputData = outputTensor.data
console.log('Processed Logits Before Softmax:', outputData)
// this function converts the model output (raw logits) into probabilities.
// E.g. [0.1, 0.2, 0.7] -> [0.2, 0.3, 0.5]
function softmax(logits) {
const expValues = logits.map((x) => Math.exp(x - Math.max(...logits)))
const sumExp = expValues.reduce((a, b) => a + b, 0)
return expValues.map((v) => v / sumExp)
}
// Convert logits into probabilities using softmax.
const probabilities = softmax(outputData)
console.log('Probabilities:', probabilities)
// Determine the class with the highest probability.
// The highest probability corresponds to the predicted sentiment.
const predictedClass = probabilities.indexOf(Math.max(...probabilities))
// 0 -> Negative, 1 -> Positive
const labels = ['Negative', 'Positive']
return `Predicted class: ${labels[predictedClass]} (Confidence: ${(
probabilities[predictedClass] * 100
).toFixed(2)}%)`
}
window.runInference = runInference
</script>
<p id="msg"></p>
<textarea id="userInput" rows="4" cols="50"></textarea>
<button
onclick="runInference(document.getElementById('userInput').value).then((output) => document.getElementById('msg').innerText = output)"
>
Run Inference
</button>
Have you used ONNX? I would love to hear your experience.