- Published on
Securing AI adoption
- Authors

- Name
- Parminder Singh
AI adoption is accelerating across industries, transforming how businesses operate and innovate. As companies embrace AI, it's crucial to understand the security and privacy implications. On a high level, AI is being integrated into business operations in three primary ways:
- AI as a Service (AIaaS): Companies use third-party AI services for specific tasks, such as image recognition or natural language processing. E.g. Google Cloud Vision API.
- AI Integration: Companies integrate AI into existing systems and processes to automate tasks, analyze data, and provide insights. E.g. using code suggestions in integrated development environments (IDEs).
- Custom AI Solutions: Companies build custom AI models to address specific business needs, leveraging proprietary data and gaining competitive advantages. E.g. training a model to predict customer churn.

Photo by Amanda Dalbjörn Unsplash
This article will explore security considerations when building custom AI solutions and integrating AI into business operations. Before diving into security, let's quickly review why companies might be creating custom AI solutions and what the training model process looks like.
Here are some key reasons why companies might choose to build custom LLMs.
Specialized Knowledge Needs: Custom LLMs can be tailored to understand and generate text based on specific technical domains and specialized fields of knowledge.
Data Privacy and Security: Companies can ensure that their sensitive data, proprietary information, and customer data are handled securely and in compliance with data protection regulations.
Integration and Customization: Custom LLMs can be better integrated into existing workflows, systems, software applications, technical infrastructure and business processes, optimizing performance and user experience.
Control Over Updates and Maintenance: Control over the timing and nature of model updates and maintenance schedules.
Cost Efficiency at Scale: Investing in custom LLM development can be more cost-efficient in the long run compared to paying for usage of pre-built models provided by cloud service providers.
Ethical and Bias Considerations: Models can be tailored to better align with ethical standards and reduce biases. Because of greater control over the training data, biases can be mitigated ensuring the model's outputs are fair and aligned with organizational values.
Language and Localization Needs: Custom LLMs can be developed to understand and generate text in less common languages or dialects not well supported by general-purpose models.
A training model in the context of machine learning and artificial intelligence refers to the process of teaching a computer system how to make predictions or decisions based on data. This process involves using a specific algorithm to enable the computer to learn from and interpret data, improving its accuracy over time as it is exposed to more information. The term "model" itself refers to the mathematical and computational representation of the real-world process or system being studied or emulated. Here's a simplified breakdown of the training model process.
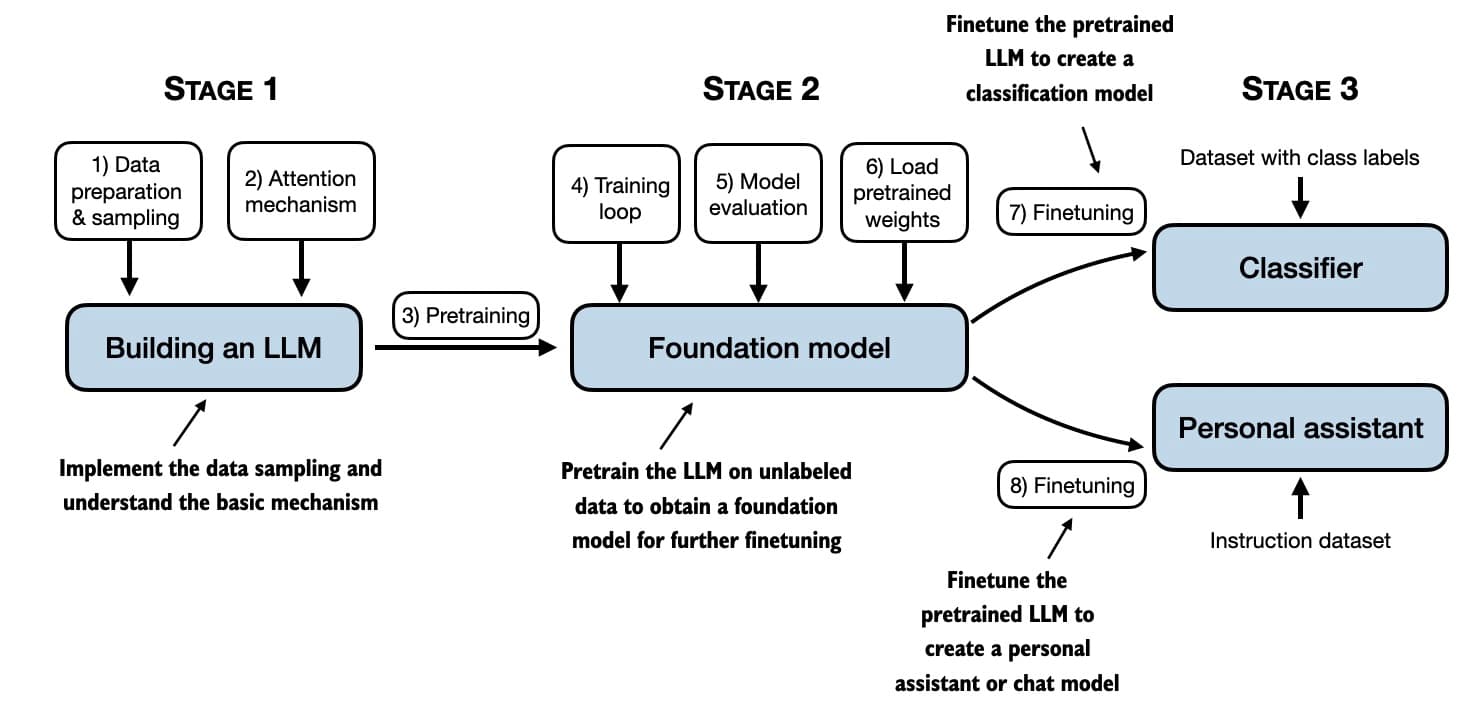 From book Build a Large Language Model by Sebastian Raschka
From book Build a Large Language Model by Sebastian RaschkaData Collection: Gathering a large and relevant dataset is the first step. This data can include anything from numbers and text to images and sounds, depending on what the model is being designed to do.
Data Preparation: The collected data is then cleaned and organized. Errors and irrelevant information are removed. Data is transformed into a format that can be easily consumed by the model.
Choosing a Model: The right machine learning model is chosen based on the specific task the model is being trained to perform. This could be a decision tree, a neural network, or any other model that best fits the data and the task at hand.
Training the Model: The selected model is trained using the prepared dataset. This involves feeding the data into the model so that it can learn from it. The model makes predictions or decisions based on the data, and adjustments are made to the model's parameters when it makes incorrect predictions. This process is repeated many times, with the model gradually becoming more accurate as it learns from its mistakes.
Evaluation: After the model has been trained, it is tested with a new set of data it hasn't seen before. This step is crucial for evaluating how well the model has learned and how accurately it can make predictions or decisions.
Tuning: Based on the evaluation, adjustments might be made to improve the model's performance. This could involve retraining the model with different parameters or providing it with more data to learn from.
Let's now delve into the security considerations. On a high level, securing AI efforts involves the following key areas.
Data Protection: AI systems often require access to vast amounts of data, including personal and sensitive information. Ensuring that this data is collected, stored, and processed securely to prevent unauthorized access or data breaches is essential. Encryption, access controls, and secure data storage solutions is critical.
Data Privacy: Systems should be designed to respect user privacy, including mechanisms for data anonymization, consent management, and users' rights to access, correct, or delete their data. This is particularly important in light of data protection regulations like the GDPR and CCPA.
Ethical Use of AI: Ensuring that AI systems are used ethically involves addressing concerns around bias, fairness, and transparency. Organizations should implement ethical AI frameworks that include guidelines for the responsible use of AI, regular audits for bias and fairness, and transparency in AI decision-making processes.
Security of AI Systems: AI systems themselves can be targets for cyber attacks, including model theft, adversarial attacks (where inputs are designed to trick the AI into making incorrect decisions), and data poisoning (altering the data the AI learns from to influence its behavior). Robust security measures to protect AI models should be implemented.
Explainability and Accountability: AI systems should be designed to provide explainable decisions. This not only helps in building trust among users but also aids in regulatory compliance by ensuring decisions made by AI can be understood and justified.
Compliance and Governance: Industry-specific regulations that may apply to AI use in areas like healthcare, finance, or autonomous vehicles should be adhered to. Establishing a governance framework for AI use can help ensure compliance and manage risks.
Risk Assessment and Management: Conducting thorough risk assessments of AI systems can help identify potential security and privacy risks and their impact. This should be an ongoing process.
The OWASP Top 10 for Large Language Model Applications
The Open Web Application Security Project (OWASP) top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications.

1. Prompt Injection
LLMs can be susceptible to injection attacks where malicious inputs are designed to manipulate the model's output. Attackers could input specially crafted prompts to elicit private information or biased responses. Mitigating these requires rigorous input validation and sanitization, along with training models to recognize and resist malicious inputs.
2. Insecure Output Handling
LLMs can generate outputs containing vulnerabilities, such as malicious code or sensitive information. E.g. you create an API that that queries an AI system to generate some code and blindly run that code. This can lead to variety of attacks like code injection, command injection, and more. To mitigate this risk, take a zero-trust approach, validate & sanitize all output and encode LLM output to prevent code execution.
3. Training Data Poisoning
Attackers might attempt to manipulate the training data of LLMs to influence their behavior. This can lead to biased outputs, misinformation, or other malicious outcomes. Employing robust data validation and integrity checks, along with regular audits of training data, can help mitigate these risks. Regular audits of training data, verifying external data sources and maintaining ML-BOM records can help.
4. Model Denial of Service
LLMs can be targeted with denial-of-service attacks, where attackers overwhelm the model with requests, leading to performance degradation or unavailability. Implementing rate limiting, request validation, and scalable infrastructure can help mitigate these risks.
5. Supply Chain Vulnerabilities
LLMs often depend on a variety of third-party libraries and tools. Supply chain vulnerabilities stem from outdated software, susceptible pre-trained models, poisoned training data, insecure services & components. Regular vulnerability scanning, timely updates of dependencies, signing models & code, applying anomaly detection and monitoring are some of the strategies to mitigate this risk.
6. Sensitive Information Disclosure
LLM applications may disclose sensitive information, proprietary algorithms, or confidential data, leading to privacy violations and intellectual property theft. Implementing access controls, encryption, and secure data handling practices can help mitigate these risks.
7. Insecure Plugin Design
Vulnerabilities in plugins or extensions used with LLMs can create entry points for attackers. These attacks can lead to data exfiltration, remote code execution, or unauthorized access. Adding type checks & validating parameters, SAST scans, and secure code practices, secure plugin architecture reviews can help mitigate these risks.
8. Excessive Agency
LLMs can exhibit excessive agency, generating outputs that are too convincing or misleading. This can be exploited for misinformation, social engineering, or fraud. Implementing explainability and transparency in AI decision-making, and regular audits for bias and fairness can help mitigate these risks.
9. Overreliance
Overreliance on LLM outputs without human oversight can lead to errors, misinformation, or unintended consequences. Blindly trusting LLM outputs without human validation can be risky, especially for sensitive tasks. Implementing human-in-the-loop validation, model explainability, and regular audits can help mitigate these risks.
10. Model Theft
This refers to unauthorized access or copying of proprietary LLMs or training data. This can risk in economic loss, reputation damage and unauthorized access to sensitive data. Robust intellectual property protection, access controls, and data security measures are crucial safeguards.
Please note that the OWASP Top 10 for Large Language Model Applications is a work in progress and the list of vulnerabilities and mitigations may evolve over time. The above listing is based on the official 1.1 release.
Adopting AI is a strategic imperative for organizations, but it's important to consider the security and privacy implications. Building custom AI solutions and integrating AI into business operations requires a security-first mindset. Understanding the potential risks and vulnerabilities, and implementing robust security measures, is essential to ensure that AI systems are secure, ethical, and compliant with regulations. By addressing these risks, organizations can build and deploy AI systems that are secure, trustworthy, and resilient to attacks.